


Elasticsearch 分页查询
关于 Elasticsearch 分页查询,这几个问题经常被问到:
- 一次性获取索引上的某个字段的所有值(100 万左右),除了把 max_result_window 调大 ,还有没有其他方法?
- 每次拿 20 条数据展示在前台,然后点击下一页,再查询后面的 20 条数据,应该要怎么写
- From+size、Scroll、search_after 的本质区别和应用场景分别是什么?
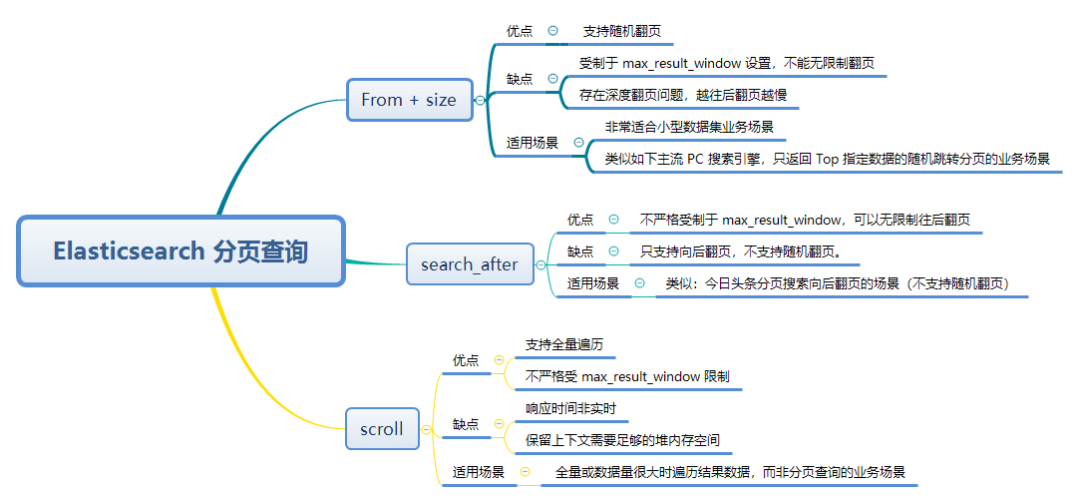
Elasticsearch 支持的分页方式
- From + Size
- Scroll
- Search After
下面我就三种方式的联系与区别、优缺点、适用场景等展开进行解读。
From + size
语法
GET /index_name/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}- from:定义了当前页返回数据的起始位置,默认为 0。
- size:定义了当前页返回数据的文档数量,默认为 10。
优缺点
优点:支持随机翻页
缺点:
- 受制于
max_result_window的设置,不能无限制翻页 - 存在 深度翻页 的问题,越往后翻页越慢
max_result_window 问题
Elasticsearch 会限制最大分页数,避免大数据量的召回导致性能低下。
Elasticsearch 的 max_result_window 默认值是 10000。也就意味着:如果每页有 10 条数据,会最大翻页至 1000 页。
实际主流搜索引擎都翻不了那么多页,举例:百度搜索“上海”,翻到第 76 页,就无法再往下翻页了,提示信息如下:
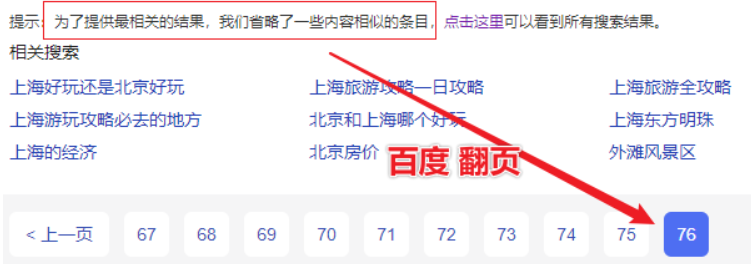
如下的分页查询:
GET index_name/_search
{
"from": 0,
"size":10001
}
GET index_name/_search
{
"from": 10001,
"size":10
}会报错:
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
]
}
}原因就是请求的数据集超过了 ES 默认的最大窗口限制,index.max_result_window 默认值为 10000。
报错信息中还给出了两个解决方案:
方案一:大数据集召回数据使用 scroll api
方案二:增大
index.max_result_window默认值
PUT index_name/_settings
{
"index.max_result_window":50000
}注意:修改这个设置可能需要对集群进行额外的硬件投入,因为处理大量数据时对资源的需求会显著增加。
深度分页问题
比如这个查询:
GET index_name/_search
{
"from": 10001,
"size": 10
}搜索请求通常跨越多个分片,每个分片必须将其请求的命中内容以及任何先前页面的命中内容加载到内存中。也就是说,每次查询都需要从头开始计数到 from 参数所指定的位置,然后返回从那里开始的 size 数量的文档。
上述例子中,ES 会将 10011 条数据加载到内存中,然后经过后台处理,再返回最后 10 条我们想要的数据。
那也就意味着,越往后翻页(也就是深度翻页)我们需要加载的数据量越大,对于翻页较深的页面或大量结果,这些操作会显著增加内存和 CPU 使用率,从而导致性能下降或节点故障。
form size 分页原理
在 Elasticsearch 中,索引被分割成多个分片,这些分片可以分布在不同的服务器上。这种设计的目的是为了提高系统的可伸缩性和容错性。
因此,Elasticsearch 在处理查询时,会在所有相关的分片上执行查询,并将初步结果集汇总到协调节点。
协调节点必须处理来自每个分片的部分结果,然后汇总这些数据以形成最终的响应。
当 from 值较大时,协调节点需要处理和排序的数据量显著增加,从而增加了处理每个查询的负担。
适用场景
第一:非常适合小型数据集或者大数据集返回 Top N(N <= 10000)结果集的业务场景。
第二:类似主流 PC 搜索引擎(谷歌、bing、百度、360、sogou等)支持随机跳转分页的业务场景。

Scroll
Scroll API 是 Elasticsearch 用来处理大量数据检索的一种机制,它特别适合于需要导出或处理大量结果集的场合。
核心执行步骤
1. 初始化 Scroll 会话
首先初始化一个 scroll 会话:
POST /index_name/_search?scroll=1m // 保持滚动窗口1分钟
{
"size": 100,
"query": {
"match_all": {}
},
"sort": [
"_doc" // 使用文档顺序来优化性能
]
}scroll参数:
当你首次发送一个带有 scroll 参数(如 1m 表示每个滚动请求有 1 分钟的有效期)的查询时,Elasticsearch 会创建一个快照(snapshot)或称为上下文(context),这个快照包含了查询时刻的所有匹配文档的信息。
这个快照会保持一段时间(例如 1 分钟),在这段时间内,即使底层数据发生了改变,快照的内容也保持不变。
使用
_doc作为排序参数在使用 Scroll API 时的优化意义主要体现在性能和效率上。_doc是一种内部的排序方式,代表按文档存储在磁盘上的顺序进行排序。这种排序方式最小化了查询操作的开销,因为它遵循了文档在物理存储上的顺序,从而减少了磁盘I/O操作和提高了数据的读取速度。当您的需求是遍历整个索引中的所有文档,而不关心它们的返回顺序时,使用
_doc排序可以显著提升性能。这在执行大规模数据迁移、备份或分析时尤为有用,因为这些操作通常需要处理大量数据而不需要特定的排序。
2. 持续获取数据
然后使用返回的 scroll_id 获取下一批数据:
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAxV4WVmpa..."
}随着初次查询的执行,Elasticsearch 会返回第一批结果和一个 scroll_id。你需要使用这个 scroll_id 来请求下一批结果。
你可以重复使用返回的新 scroll_id 来持续获取后续的数据批次,直到数据集的末尾。
特点
Scroll 查询在后端占用资源较多,因为它们需要在服务器上持续保持查询状态。因此,使用完成后必须显式清除 scroll 上下文,以释放这些资源。
如果未及时清除,scroll 上下文会在其超时后自动过期,但这期间内可能会对集群性能造成影响。
Scroll 提供了稳定的数据视图。意味着即使在滚动读取期间索引发生变化(如文档被删除或修改),返回的数据也不会受到影响,保证了数据的一致性。
优缺点
优点:
能够处理大量数据,不受单次查询大小限制
保持搜索上下文的一致性,即使索引在滚动期间发生变化。
缺点:
- 不适合实时用户交互。
- 占用资源较多,因为需要在 Elasticsearch 集群中维护状态信息。
- 滚动窗口过期后,需要重新开始。
适用场景
- 全量或数据量很大时遍历结果数据,而非分页查询
- 官方文档强调:不再建议使用 scroll API 进行深度分页。如果要分页检索超过 Top 10,000+ 结果时,推荐使用:PIT + search_after
search_after
核心执行步骤
1. 准备初始查询
首先,你需要准备一个查询请求,并指定排序字段,因为 search_after 需要基于一组定义好的排序字段来获取下一页数据。
POST /index_name/_search
{
"size": 1000, // 指定每页的文档数量
"query": {
"match_all": {} // 或者任何其他具体的查询
},
"sort": [
{"timestamp": "asc"}, // 主要排序字段
{"_id": "asc"} // 通常添加 _id 作为次要排序以确保唯一性
]
}2. 执行查询并保存最后一条记录的排序值
执行初始查询后,你需要从返回的最后一条记录中保存排序字段的值。
这些值将用于后续查询中的 search_after 参数。
3. 使用 search_after 参数重复地进行后续查询
在收到上一个查询的响应后,使用最后一条记录的排序值进行下一个查询:
GET /index_name/_search
{
"size": 1000,
"query": {
"match_all": {}
},
"sort": [
{"timestamp": "asc"}, // 确保至少有一个唯一的排序字段
{"_id": "desc"}
],
"search_after": ["2024-06-20T12:46:29.711Z", "last_id_in_previous_batch"] // 上一批次的最后一个文档的排序字段值
}- sort 参数进行排序
- search_after 参数需要传入上一批次查询结果中的最后一个文档的排序字段值
注意事项:
- 排序字段的选择:确保使用的字段有稳定的增量值,通常是时间戳或数字字段,以避免任何可能的重复或遗漏。
- 性能和效率:
search_after方法依赖于排序,可能需要对所使用的字段进行适当的索引优化。 - 唯一性保证:通常结合
_id字段使用,以确保记录的唯一性,特别是在基于非唯一字段排序时。
search_after 查询原理
search_after 的核心是使用上一页中最后一条记录的排序字段值来开始检索下一页的数据。这种方法通过跳过已经检索过的数据,直接从上一次的结束点开始,使得数据检索更加高效。
前置条件:使用 search_after 要求所有请求都使用相同的排序规则,以确保数据的连续性和一致性。不同的排序会导致数据的不一致性,从而影响翻页的准确性。
Tiebreaker
search_after 通常用于实现深度分页。为了确保分页的一致性和精确的数据排序,特别是在多个文档可能具有相同排序值的场景中,通常需要一个额外的排序字段作为 tiebreaker(决定因子)。
通常,_doc ID 用作 tiebreaker,因为它保证了每个文档的唯一性和稳定的排序顺序,即便是在多个文档有相同的主排序字段时。在实际应用中,你应该在 sort 参数中包括 _id 或其他唯一字段作为 tiebreaker。
在上面的例子中,_id 作为 tiebreaker 来确保即使有多个文档的 timestamp 相同,结果的顺序也是一致和可预测的。
Point in Time
PIT(Point-In-Time)是 Elasticsearch 中的一个特性,它允许用户创建一个查询的快照。这个快照代表了在特定时间点上索引的状态,确保在使用如 search_after 这类深度分页技术时,即便索引数据在查询过程中发生变更(如文档被添加、删除或修改),返回的结果依然是一致的。这类似于数据库中的事务隔离,允许进行一致的读取而不受并发写入操作的影响。
没有 PIT
如果不使用 PIT,search_after 依然可以正常工作,但后续查询可能会受到并发数据写入(如插入、删除、更新)的影响,这可能导致数据重复或漏读。
使用 PIT
数据视图稳定性:PIT 为搜索创建了一个快照,确保在 PIT 生命周期内,搜索结果不受并发更新的影响。这意味着即使数据发生变化,查询的上下文仍然是创建 PIT 时的状态。
一致性:PIT 保持查询的上下文不变,使得使用 search_after 进行多次翻页时,每页返回的数据都是基于同一数据快照的。这在多用户环境中尤其重要,因为它防止了用户看到因并发数据修改而导致的不一致结果。
结合 PIT 和 search_after 的使用实例
1. 创建 Point-in-Time (PIT)
首先,你需要创建一个PIT来获取一个稳定的视图,这样即使数据更新,查询结果也不会改变。
POST /index_name/_pit?keep_alive=1m假设返回的响应是这样的:
{
"id": "46ToAwMDaWR5BXV1ZXJ5AndB..."
}2. 初始查询与 search_after
进行初始查询时,不使用 search_after,而是设置排序规则,并将 PIT ID 包括在请求中。
POST /_search
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{ "timestamp": "asc" },
{ "_doc": "asc" }
],
"pit": {
"id": "46ToAwMDaWR5BXV1ZXJ5AndB...",
"keep_alive": "1m"
}
}注意:
- 使用 PIT 进行检索时,通常不需要再指定具体的索引名称。PIT 本身就是基于特定索引或索引的集合创建的,所以查询时只需引用 PIT ID 即可。
- 如果在使用 PIT 时仍然指定了索引名称,这通常会导致请求失败,并返回一个错误。
- 因为 PIT 与特定的索引状态相关联,指定索引可能会导致冲突或查询逻辑混乱,因为 ES 不确定应该优先考虑哪个索引指示——是 PIT 中封装的索引状态还是请求中显式指定的索引。
3. 使用 search_after 进行后续查询
在获取到初始查询的结果后,从最后一条记录中提取出排序值,用于 search_after 参数。
假设初始查询的最后一条记录的排序值是 ["2024-06-21T07:46:54.696Z", 142],接下来的查询将使用这个值来获取下一页数据。
POST /_search
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{ "timestamp": "asc" },
{ "_doc": "asc" }
],
"search_after": ["2024-06-21T07:46:54.696Z", 142],
"pit": {
"id": "46ToAwMDaWR5BXV1ZXJ5AndB...",
"keep_alive": "1m"
}
}4. 关闭 PIT
完成所有分页查询后,你需要关闭PIT,以释放服务器上的资源。
DELETE /_pit
{
"id": "46ToAwMDaWR5BXV1ZXJ5AndB..."
}这个流程确保了查询的一致性,即使在数据频繁变化的环境中也能保持结果的稳定。每次查询都应根据需要调整 keep_alive 参数,以保持 PIT 的有效性直到查询完成。
优缺点
优点:不严格受制于 max_result_window,单次请求值不能超过 max_result_window,但总翻页结果集可以超过,所以可以无限制往后翻页。
缺点:不能随机访问任意页,必须按顺序访问。
适用场景
类似:今日头条分页搜索 https://m.toutiao.com/search
不支持随机翻页,更适合手机端应用的场景。

总结
- From+ size:需要随机跳转不同分页(类似主流搜索引擎)、Top 10000 条数据之内分页显示场景。
- Scroll:需要遍历全量数据场景 。
- search_after:仅需要向后翻页的场景及超过Top 10000 数据需要分页场景。
- max_result_window:调大治标不治本,不建议调过大。
- PIT:本质是视图。
本文说法有不严谨的地方,以官方文档为准。
参考: